インフラ素人がOpenShift・K8s現場に放り込まれた話
はじめに
AWSでデプロイ経験はあれど、「アドレスバーを叩いてサーバーに行ってDCからデータが返ってくる」くらいにしか知らなかった私が、オンプレのOpenShift基盤運用チームに参画することになった。
基本設計書を読んでも用語が全くわからない。フロー図を見てもその用語が何をしているのかわからない。一つずつ調べていくうちに、ソフトウェア制作とは全く違う世界があることを知った。
チーム構成と役割
6人チームの構成はこうだった。
- オンプレ担当 3名(私はここ)
- DevOps担当 2名
- リーダー 1名(各種対応)
DevOpsの2名はZabbixやPrometheusでログチェック、OCP・LVMSのアップデート、GitLabからConfigを作ってプロキシを挟んでCI/CD。applyしてGitと同期する、というのが主な仕事だった。
面白かったのは Chaos Mesh の存在だ。本番に近い環境で意図的に障害を起こし、システムの耐障害性を確認する手法で、「壊れても大丈夫か」を事前に確かめる発想がインフラらしいと感じた。
私の定常業務
私が毎日やっていたのはこういう作業だ。
- 新規NameSpaceの追加
- ResourceQuotaの変更
- SCC設定(restricted → baseline)
- VIPの払い出しと削除
- 砂場(sandbox)の削除
手順はこうだ。NameSpaceの台帳から手順書に数値を写してConfig作成 → レビュー → TeraTerm で踏み台サーバーから oc(OpenShiftコマンド)でプロキシ+ファイアウォールを経由して入力 → K8s APIでリソース値がクラスターに反映される。
ログに created と出れば正常。確認者・上層部・立ち合いのもと、制限時間も申告してある。台帳と数値が合わなかったりしてエラーになると焦る。何事もなければ20分ほどで終わる。
シンプルに見えて、本番クラスターに直接触れている緊張感は毎回あった。
ResourceQuotaの厳しさ
依頼側(アプリを作る側)がResourceQuotaの増量を申請するには、試験をして以下の根拠を出さなければならない。
- L.RCPU / L.RMEM(Limit CPU・Memory)
- PSTR(ストレージ)
- PODs数
- ピーク時の差分
「実績値 + JVM内訳 + 負荷試験ピーク」の三点セットがないと承認できない。
最初は厳しいと思ったが、理由がわかってきた。クラスターのリソースは有限で、一つのNameSpaceが暴走すれば他に影響が出る。だから根拠のない増量は認められない。共有インフラの責任とはこういうことかと理解した。
インフラ未経験者が驚いたこと
「クラウド」の実体
クラウドという言葉が曖昧なままだったが、ちゃんとデータセンターの物理サーバーに入っている。AWSで公開とは実体はこうだ。AWSの東京DC内の物理サーバー ↓ 仮想マシン(EC2インスタンス) ↓ その一区画を月額数ドルで借りているつまりAmazonのDCを「間借り」しているということ。スマホで撮った写真がすぐにPCに同期するのも、高速でデータセンターに送ってそれが返ってきているだけだ。
アドレスバーを叩いてから返ってくるまで
これが一番の驚きだった。アドレスバーを叩いてデータが返ってくるまでに、こんなにも多くのやり取りと関所を高速で通り抜けているとは思っていなかった。
OSI参照モデル、10進数から2進数への変換、LINEと電話の通信の違い——この案件に参画しなければ調べることもなかった。
セキュリティの考え方
ホワイトリスト、ゼロトラスト、IAM、どのIPなら許可するか——セキュリティの根本的な考え方を初めてちゃんと理解した。
使うイメージ(コンテナイメージ)にもウイルスが含まれている可能性があるので、それもスキャンしているということも知った。
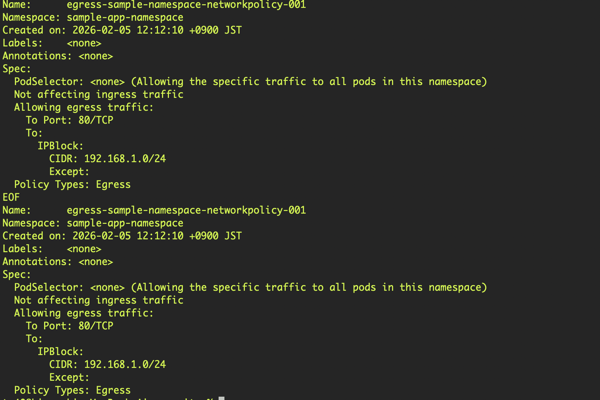
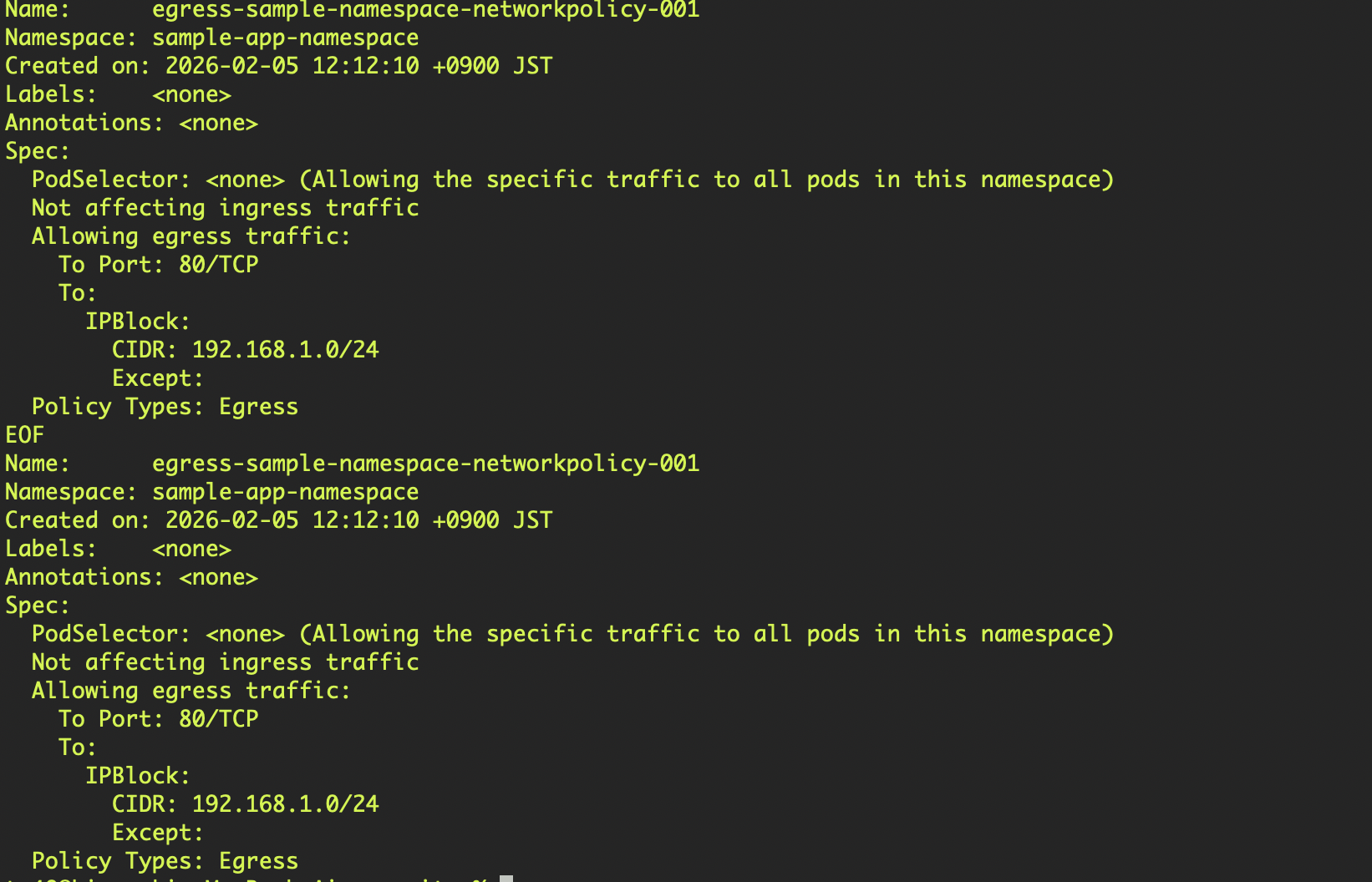 実際のoc describeコマンド出力。EgressトラフィックをCIDRで制限している様子。
実際のoc describeコマンド出力。EgressトラフィックをCIDRで制限している様子。
Kubernetesとは何か(素人の解釈)
難しいが、自分なりの理解はこうだ。
K8sはでっかいコンテナ管理システムで、Podが壊れたり間違って消しても自動で再生する。
ファミコン(ハードウェア)をソフトウェア化したのがOpenShift。その中にコンテナ(K8s)を作る。中のサーバーはDB・WEB・APP。
データセンターはスクリプトでGETやPUTやバージョンアップができる。これがインフラのソフトウェア化(IaC)の本質だと理解した。
結論
常に通信が止まらない仕組みで運用・保守されている。
夜勤やトラブルがあれば商用環境で対応しなければならない人たちがいる。私たちの快適な通信は、このような保守があって成り立っている。
短い期間だったが、ソフトウェア開発者として見えていなかった世界の一端を見た。インフラを知ることで、アプリケーションの設計に対する考え方も変わった気がする。
この記事はオンプレOpenShift基盤の運用チームに参画した実体験をもとに書いています。技術的な詳細よりも「未経験者の目線で何が見えたか」に焦点を当てています。